题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。(i)从加速数模型中求出OLS残差,并用回归
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。(i)从加速数模型中求出OLS残差,并用回归
本题利用INVEN.RAW中的数据;也可参见计算机习题C11.6。
(i)从加速数模型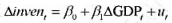 中求出OLS残差,并用
中求出OLS残差,并用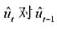 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
(ii)用PW估计这个加速数模型,并将β1的估计值与OLS估计值进行比较。你为什么预期它们很相似?
 答案
答案
查看答案


 。这对于OLS来说有何含义?
。这对于OLS来说有何含义?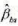 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?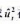 在整个样木中的平均值、最小值和最大值。
在整个样木中的平均值、最小值和最大值。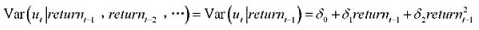
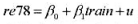 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
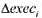 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?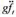 。
。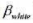 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。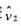 。(回归中包含的其他变量可参见表15.1.)用这些来检验educ是否外生; 也就是说,判断OLS与Ⅳ之间的差异在统计上是否显著。
。(回归中包含的其他变量可参见表15.1.)用这些来检验educ是否外生; 也就是说,判断OLS与Ⅳ之间的差异在统计上是否显著。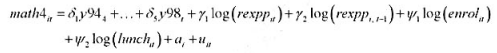
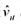 。
。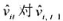 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。