题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
(i)利用WAGE PRC.RAW中的数据,估计习题11.5中的分布滞后模型。用回归(12.14)来检验AR(1)序列相
(i)利用WAGE PRC.RAW中的数据,估计习题11.5中的分布滞后模型。用回归(12.14)来检验AR(1)序列相
关。
(ii)用迭代的科克伦-奥卡特方法重新估计这个模型。长期倾向的新估计值是多少?
(iii)用迭代C0求出LRP的标准误。(这要求你估计一个修正方程。) 判断LRP估计值在5%的水平上是否统计显著异于1?
 答案
答案
查看答案

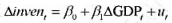 中求出OLS残差,并用
中求出OLS残差,并用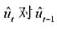 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?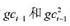 的回归来检验异方差。你有何结论?
的回归来检验异方差。你有何结论?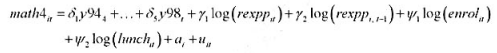
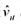 。
。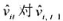 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
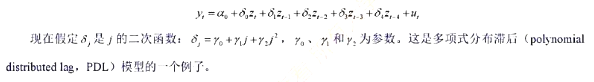
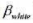 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。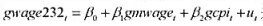 并检验误差中的AR(1)序列相关。假定回归元是严格外生的。误差中有正或负的序列相关吗?
并检验误差中的AR(1)序列相关。假定回归元是严格外生的。误差中有正或负的序列相关吗?